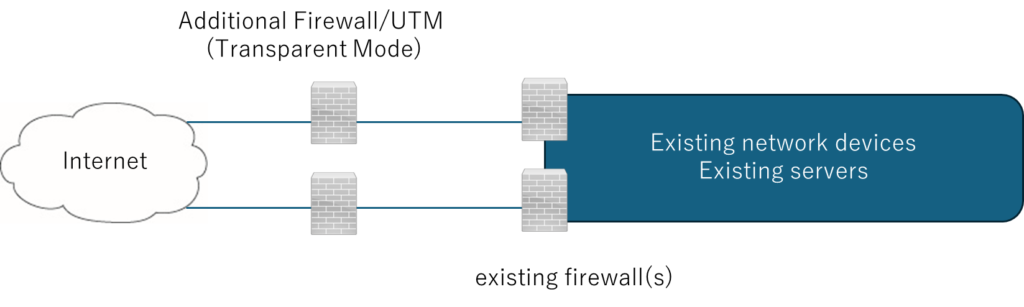
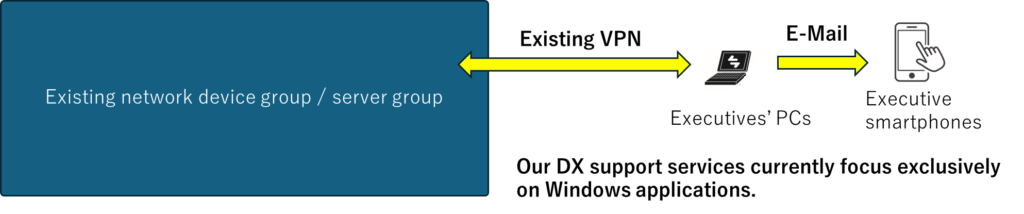
During the test, the WAN-side cable of the firewall was removed and immediately reinserted, simulating a real inline deployment operation.
The test was performed multiple times under identical conditions. The maximum observed interruption window was used for evaluation, to reflect a conservative estimate suitable for real-world deployment planning.
In many legacy enterprise environments, network topology evolves without being redesigned. Devices are added over time, but rarely removed. The result is an architecture with over twenty devices performing overlapping or redundant roles.
In one recent case, we proposed a radical simplification: consolidating more than twenty devices into just four firewalls.
The target architecture consisted of:
External Firewall (Primary)
External Firewall (Secondary)
Internal Firewall (Primary)
Internal Firewall (Secondary)
This was not merely a hardware reduction. It was a redesign of responsibility, routing, segmentation, and operational logic.
Direct WAN Termination on Firewalls
The original environment included multiple routers terminating various WAN circuits. Instead of maintaining separate routing devices, we made a deliberate decision:
Terminate WAN circuits directly on the firewall
Eliminate standalone routers entirely
Modern firewalls are fully capable of handling WAN termination, dynamic routing, policy routing, and redundancy. Keeping routers “because that’s how it has always been done” adds cost without increasing resilience.
By collapsing routing and security into the firewall layer, we reduced devices and simplified failover design.
Segment-Specific Default Routes
Instead of using a single upstream path for all traffic, we implemented:
Separate default routes per LAN segment
Each segment was intentionally given its own outbound path policy. This approach improved traffic control, enabled cleaner security zoning, and removed the need for complex L2 workarounds.
Design replaces bandwidth as the primary performance tool.
Eliminating All L2 Switches via Firewall VLAN Control
Modern firewalls allow direct VLAN configuration and segmentation control. Therefore:
All downstream Layer 2 switches became unnecessary
Rather than ignoring available firewall interfaces, we used them deliberately. When a firewall provides switch-like port density and VLAN control, placing a Layer 2 switch beneath it “by default” wastes both capital and architectural clarity.
Reducing switching layers:
Decreases failure points
Reduces broadcast domain ambiguity
Simplifies troubleshooting
Improves total asset efficiency
Port cost matters. Unused firewall interfaces represent hidden capital waste.
Security Expansion via License Modification
The consolidation strategy also improved future security posture. Instead of purchasing new appliances:
IPS and WAF capabilities can be activated through license changes
Security evolution becomes a software decision, not a hardware replacement project. This dramatically improves capital efficiency and deployment speed.
Built-in WLC for Future Wireless Expansion
The firewall platform includes a Wireless LAN Controller function enabled by default. This provides:
Immediate readiness for future wireless AP deployment
Unified security and wireless policy control
Improved cost-performance ratio during expansion
When wireless infrastructure is introduced later, no separate controller appliance is required. The architecture scales without structural redesign.
Design Is the Investment
The consolidation from over twenty devices to four was not a budget cut. It was a design correction.
Overinvestment in hardware often masks underinvestment in architecture. True efficiency does not come from adding devices, but from redefining their roles.
Twenty-plus devices were reduced to four. Routers were removed entirely. Switch layers were eliminated. Security features became license-driven rather than hardware-driven.
By adopting a firewall/UTM from a different vendor than the existing one, a layered defense strategy is achieved.
Theoretical Maximum Downtime: 10 Seconds
The “within 10 seconds” requirement is based on the Layer-1 keepalive timer.
Transparent Mode: A device that operates like a Layer-2 switch while functioning as a firewall/UTM.
The discovery timing of newly identified vulnerabilities will be the same for manufacturers that adopt open algorithms.
At the link below, we introduce firewall/UTM vendors whose products are more closed in design. (Please note that the content may remain in Japanese.) Internal link
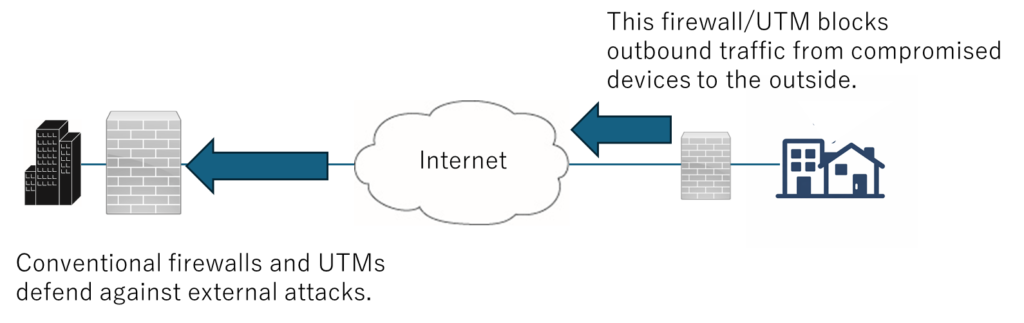
Compromised Home Routers Used as Attack Proxies
Home Routers as Attack Proxies
Compromised Consumer Routers for External Attack Proxying
Consumer Router Botnets Used for External Attacks
The FW/UTM on the right side of the diagram blocks outbound traffic from compromised devices from reaching external networks.
The above firewall/UTM is assumed to operate in transparent mode (functioning as an L2 switch while providing firewall/UTM-equivalent protection).
A Tool That Further Supports Our GenAI-Driven DX Enablement Service
Remove micro-friction from development so leadership can keep the tempo.
Visual Studio automation as RPA
When you’re not sure where to click in a GUI like Visual Studio, GenAI uses Python-based automation to move the mouse and click for you. This eliminates “cursor confusion” during screen sharing sessions, allowing you to maintain the pace of implementation, decision-making, and validation. This idea is free.
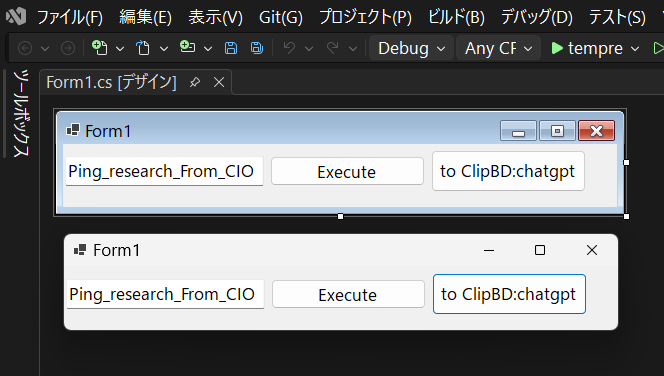
Deterrence created when a CIO uses on-site operational terminology.
Confirm you are logged into the intended target.
Deterrence created when a CIO uses on-site operational terminology.
Ping_research_From_CIO
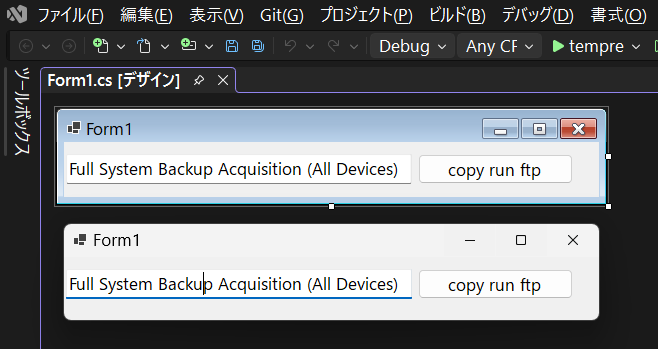
Deterrence created when a CIO uses on-site operational terminology.
Full System Backup Acquisition (All Devices)
Deterrence created when a CIO uses on-site operational terminology.
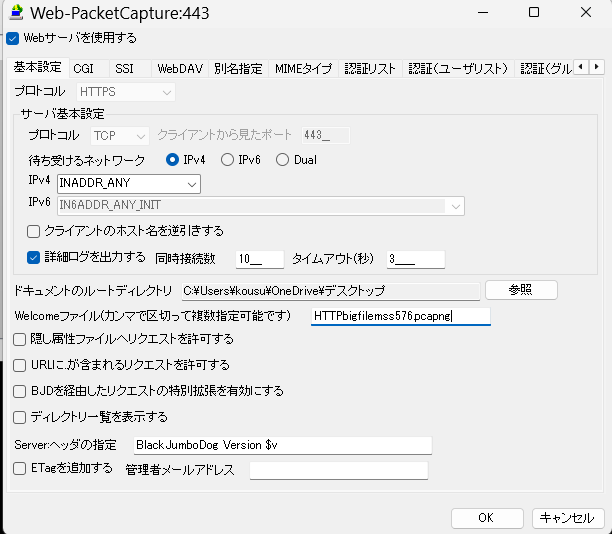
Download large files from a browser using a protocol that does not congest the network.
Because HTTP/HTTPS packet sizes are small, the time the line is monopolized is sporadic, unlike communications such as FTP.
Use externally issued server certificates; self-signed certificates are not recommended.
If a packet capture result file is specified as the welcome file, the download will start as soon as the web server is accessed.
BJD is a paid service, but it is sufficiently mature, and a sufficient number of bugs have already been fixed.
A lightweight screenshot tool with random intervals (1–5 minutes)
This tool automatically captures snapshots of the PC screen at random intervals between 1 and 5 minutes and saves them to a designated folder. It is designed for lightweight visual logging of development, testing, and troubleshooting activities without the overhead of continuous video recording.
What it does
Captures the entire main display at random intervals (1-5 minutes).
Many existing tools cannot record images at random interval timings.
Save the screenshot in PNG format
Allow users to choose where to save
Minimal interface with only three buttons
Buttons
Select Image Storage Location
Start Recording
Stop Recording
Intended use
Visual work logs for development and verification
Evidence collection for troubleshooting and reporting
Lightweight documentation without generating large video files
File format and naming
Format: PNG
Example filename: Snap_YYYY-MM-DD_HH-mm-ss_fff.png
Optionally grouped by date in subfolders for easier navigation
Behavior
After each capture, the tool waits a random duration between 1 and 5 minutes before taking the next snapshot
Recording continues until the user presses Stop Recording
If the storage location becomes unavailable, recording stops automatically to prevent silent failures
This tool is intentionally minimal and built for clarity, reliability, and low system impact.
Sound-Based Monitoring for Servers and Network Equipment
I once deeply respected the diligence of the security personnel stationed at a data center. They noticed a reboot event by sound alone and reported it faster than any monitoring system. That experience reinforced a simple truth: the physical layer often speaks before dashboards do.
This concept monitors the physical “voice” of infrastructure: fan noise, airflow tone, vibration-related sounds, and sudden acoustic events. A small sensor node (for example, a Raspberry Pi with an I2S MEMS microphone) measures acoustic level over time, stores the data as a time series, and visualizes it as a graph. When the measured level exceeds a defined threshold, the system can notify operators by email (or other channels) as an early warning.
Logical monitoring (SNMP, syslog, metrics, logs) is already common. Sound monitoring is different: it observes the real-world environment around the hardware. In many on-prem environments—small server rooms, branch offices, clinics, factories, or shared racks—this “physical layer monitoring” can provide a practical safety net with minimal cost and complexity.
The key value is not “audio recording,” but “state detection.” Operators do not need high-fidelity sound; they need a stable signal that reflects mechanical behavior. Even a simple time-series graph can deliver reassurance: if the baseline remains stable, operators gain confidence that nothing abnormal is developing. When the signal shifts, it can indicate a real-world change worth checking on-site.
What this system measures (practical signals)
Average acoustic level over time (e.g., per 10 seconds / per minute)
Short spikes (sudden events) and sustained elevation (continuous abnormality)
Frequency-band energy (FFT) to detect “tone changes,” not only loudness
Why sound monitoring can complement existing tools
Detects physical anomalies that may not appear in SNMP/logs at an early stage
Provides a “reality check” for on-prem rooms where full telemetry is not deployed
Supports human trust: “no change on the graph” is a form of operational reassurance
Alerting and reporting
Email notification when the level crosses a threshold
Trend-based alerting (e.g., deviation from baseline rather than absolute dB)
Daily/weekly auto-generated graphs (PNG/PDF) for quick review by operators or executives
Recommended sensing approach
I2S MEMS microphone for stable digital capture and reduced analog noise sensitivity
Small Linux node for continuous operation (low power, easy replacement)
Simple storage format (CSV/SQLite) to keep the system transparent and maintainable
Where this is most useful
Small and medium on-prem server rooms without full-scale monitoring investments
Branch sites where “someone occasionally checks” is still the reality
Environments where physical deterrence matters: “We also observe the physical layer”
What makes this idea viable as a product or service
Low cost per node and simple installation
Clear differentiation: a physical-layer signal that existing tools usually ignore
Easy integration into a broader offering (on-site inspection, cabling audit, operational reporting)
Tips
Pocketalk did not recognize “ARP” when I pronounced it as “āpu” in Japanese, so I had to pronounce it as “A, R, P,” letter by letter.
“`html
Technical Inquiry
If this article relates to your network architecture, security design,
or infrastructure modernization, feel free to contact us.
Typical network architecture solutions designed and implemented by GIT.
These patterns are derived from real enterprise environments and long-term operational experience.
Resilient Satellite-Backhaul Architecture for Interference-Prone Regions
This document presents a carrier-grade satellite backhaul design optimized for post-conflict and interference-prone environments. The primary objective is not continuous uptime at all costs, but guaranteed recoverability under degraded power, packet loss, and intentional radio interference.
This architecture does not compete with satellite connectivity providers. Instead, it provides an operations-resilient overlay that runs on top of existing commercial satellite infrastructure.
Design Principles — Recovery Before Availability
Non-Competitive Overlay on Existing Satellite Networks
This design assumes the use of existing commercial satellite networks already operating in Northern Europe and adjacent regions. The goal is to strengthen operational resilience without competing with connectivity providers.
Key principles:
Use existing satellite backhaul as the underlay
Provide resilience at the network-operations layer
Support multi-operator satellite environments
Avoid replacing or competing with satellite carriers
Deliver recovery-oriented design rather than bandwidth
The system is positioned as an operations resilience layer, not a connectivity product.
L3-First Overlay Architecture (EVPN/VXLAN)
Traditional L2 extension across unstable infrastructure leads to cascading failures. Therefore, this architecture prioritizes Layer-3 VXLAN (L3VNI) segmentation.
Core components:
EVPN control plane (MP-BGP)
VXLAN data plane
L3VNI for VRF segmentation
Minimal L2 extension (site-local only when required)
Benefits:
Fault containment within VRFs
Prevention of broadcast storms and loops
Faster recovery after link degradation
Simplified post-outage convergence
This approach ensures that local misconfigurations or infrastructure instability do not propagate across the entire network.
Operations-First Connectivity (OAM VRF)
Operational connectivity is isolated into a dedicated VRF:
VRF-OAM (Operations and Management)
Functions carried within this VRF:
Device management (SSH/HTTPS)
Telemetry and monitoring
EVPN/BGP control plane
Logging and diagnostics
Remote recovery actions
Design rules:
OAM traffic shares the same satellite link as service traffic
Bandwidth requirements are minimal (sub-Mbps acceptable)
OAM traffic is strictly limited to recovery-critical functions
No large data transfers permitted in OAM VRF
Even when service traffic collapses, recovery control remains available.
Interference-Aware Satellite Operations
Jamming-Resilient Control Behavior
This design assumes persistent low-intensity radio interference such as:
Packet loss bursts
Latency fluctuations
Short intermittent outages
Throughput degradation
The objective is not to defeat jamming at the physical layer, but to prevent network instability caused by control-plane overreaction.
Key measures:
Conservative BGP and EVPN timers
Avoid aggressive failover triggers
Introduce hysteresis in path selection
Prevent control-plane flapping
Maintain stable session state under degraded conditions
The system prioritizes stability under degradation rather than rapid failover.
Minimal OAM Survival Channel
Operational traffic is intentionally constrained to a minimal footprint.
Allowed traffic:
Management access
Monitoring
Control-plane signaling
Emergency configuration actions
Disallowed traffic:
Bulk log transfers
Backups
File transfers
Heavy dashboards
Continuous telemetry streams
The objective is to ensure that OAM traffic remains viable under severe bandwidth constraints without congesting the satellite link.
Failure Sequence and Recovery Order
Recovery is orchestrated in a defined sequence:
Power stabilization
OAM VRF recovery
Control-plane re-establishment
Service restoration
The design deliberately avoids attempting full service restoration simultaneously. Instead, it ensures that operators regain control first.
Validation Using Cisco CML
Simulation Environment
Cisco Modeling Labs (CML) is used to reproduce the architecture and failure scenarios.
Simulated conditions include:
High latency satellite links
Packet loss
Link instability
Interference-like degradation
Power interruption scenarios
Failure Scenarios Tested
Service Collapse Test Service VRF failure is induced while verifying that OAM VRF remains reachable.
Interference Simulation Variable packet loss and latency introduced to emulate radio interference. Goal: prevent control-plane flapping.
Full Outage Recovery Complete link loss followed by restoration. Recovery order and convergence time are measured.
Automation and Reproducibility
Configuration and recovery procedures are automated.
Legacy TeraMacro scripts translated into Python
Automated configuration deployment
Reproducible failure injection
Publicly documented test outputs
This ensures that the architecture can be independently validated.
Collaboration Model
artnership with Satellite Operators
This architecture is designed to operate in cooperation with existing satellite providers.
Value delivered:
Operational resilience
Faster recovery after outages
Fault containment
Stable control-plane operation under interference
The design does not replace satellite connectivity. It enhances survivability and recoverability.
Deployment Context
Applicable environments:
Northern European infrastructure resilience programs
Post-conflict reconstruction
Disaster recovery communications
Power-unstable regions
Carrier ground station operations
Final Statement
The goal of this architecture is not absolute uptime.
The goal is recoverability.
When interference persists, when latency fluctuates, when power fails,
operators must retain control.
Operations survive first. Services return second.
That is the foundation of resilient communications in unstable environments.
A Permanent Regional Backhaul Using One-to-Many GRE (mGRE) Without Encryption
In regions where electrical power is unstable, satellite internet must be designed for survival rather than peak quality. Instead of pursuing traditional metrics such as throughput, latency optimization, or encryption-first security, this architecture prioritizes rapid recovery, minimal operational overhead, and tolerance for repeated device restarts.
Our approach uses multipoint GRE (mGRE) as a permanent regional backhaul fabric. Encryption is intentionally omitted at the transport layer. This eliminates key rotation, re-negotiation delays, CPU overhead, and ongoing vulnerability remediation cycles tied to cryptographic stacks. The resulting network is simpler, more resilient to power loss, and easier to maintain across remote sites.
The guiding principle is not to prevent interruption, but to ensure that communication returns immediately after interruption.
What One-to-Many GRE (mGRE) Enables in Permanent Regional Links
mGRE allows multiple remote sites to join a shared tunnel domain without defining fixed tunnel destinations. This removes the need to maintain separate point-to-point tunnels for each site and significantly reduces configuration complexity as the network grows.
For permanent regional satellite backhaul, this means:
New sites can be added without restructuring existing tunnels
Sites can drop and rejoin after power loss without manual intervention
Routing adjacency can be restored quickly after restarts
The network does not depend on stable Layer-2 state
The architecture assumes that outages will occur and focuses on rapid reintegration rather than continuous uptime.
Why Transport-Layer Encryption Is Intentionally Omitted
In unstable power environments, encryption often introduces more operational fragility than protection. Key exchange failures, CPU constraints, tunnel renegotiation delays, and security patch cycles can all delay recovery after a restart.
By omitting IPsec and similar encryption mechanisms at the tunnel layer:
No key management infrastructure is required
Tunnel re-establishment is immediate after device reboot
Firmware updates are less urgent
Operational overhead in remote areas is minimized
Sensitive payloads can still be protected at higher layers where necessary, but the transport itself remains lightweight and resilient.
NAT and Carrier Constraints in Satellite Networks
Satellite connectivity frequently involves NAT or carrier-grade NAT. This can interfere with traditional GRE operation and may introduce one-way reachability or session instability.
The design therefore assumes that:
GRE transport must tolerate intermittent reachability
Keepalive mechanisms should be minimal and lightweight
Tunnel participation must be stateless and forgiving
Where direct GRE transport is blocked, encapsulation adjustments can be applied without changing the overall architecture. The objective is not protocol purity but consistent regional connectivity.
Mutual Broadcast Model Across the Regional Fabric
Rather than forcing strict unicast recovery across unstable links, participating nodes can operate under a shared distribution model. Each site transmits into the shared tunnel domain, and receiving nodes selectively process relevant traffic.
This does not rely on native Internet multicast routing, which is rarely available across satellite providers. Instead, the shared tunnel environment provides a controlled domain where traffic distribution can occur without maintaining strict Layer-2 adjacency.
The result is a resilient communication pattern where nodes rejoin the network simply by re-establishing tunnel presence.
Using Rendezvous Points to Assist Route Recovery After Outages
To further improve recovery behavior in unstable power environments, the architecture incorporates a rendezvous point (RP) concept to assist with route re-establishment after node or link failure.
In a permanent regional backhaul where sites may power-cycle unpredictably, routing adjacency alone is not always sufficient for rapid recovery. A rendezvous point provides a stable reference node that allows participating sites to rejoin the overlay fabric without needing full mesh awareness at startup.
When a site comes back online after a power interruption:
It re-establishes its tunnel presence toward the rendezvous point
The rendezvous point serves as a temporary traffic convergence anchor
Routing information can be re-learned incrementally
Traffic can flow via the rendezvous point until optimal paths are restored
This model does not require strict multicast routing support from the underlying carrier. Instead, the rendezvous point functions as a logical convergence node within the overlay, helping stabilize routing during periods of churn.
The rendezvous point can be implemented as:
A central hub within the mGRE domain
A lightweight control-plane anchor
A temporary forwarding node during reconvergence
A regional aggregation site
Once connectivity stabilizes, traffic may again flow directly between sites if routing policy permits. The rendezvous point remains available as a fallback convergence mechanism during future disruptions.
By incorporating a rendezvous-based recovery assist mechanism, the network gains an additional layer of resilience. Rather than requiring all sites to rediscover one another simultaneously after outages, each site only needs to regain contact with a known anchor. This reduces reconvergence time and supports predictable restoration of regional connectivity.
Operational Priorities for a Permanent Regional Satellite Backhaul
To maintain stability across a long-lived regional deployment, the network is designed around predictable recovery rather than continuous uptime.
Key priorities include:
Minimal configuration state per site
Fast reintegration after power restoration
Reduced dependency on ARP or MAC learning
Simplified routing convergence
Clear separation between monitoring and transport
This approach allows the infrastructure to remain functional even as individual nodes restart, relocate, or temporarily disconnect.
Strategic Positioning
By publicly acknowledging that traditional quality metrics are not the primary design goal in unstable-power regions, this architecture establishes a distinct operational model. Later entrants may focus on performance improvements, but the foundational backhaul layer—designed for persistence and rapid recovery—remains in place.
This positions the network as a permanent regional communication fabric rather than a performance-optimized link.
“`html
Technical Inquiry
If this article relates to your network architecture, security design,
or infrastructure modernization, feel free to contact us.
Typical network architecture solutions designed and implemented by GIT.
These patterns are derived from real enterprise environments and long-term operational experience.
Monitoring tools do not have to be engineer-only. They can be customized for executive assistants and management.
Fully real-time alerting combined with AI-assisted log analysis enables detailed operational insight without relying on individual expertise.
Zabbix as the Core Monitoring Platform
This approach reduces operational risk while preserving full transparency of monitoring data. Our monitoring architecture is built around Zabbix, an open-source enterprise monitoring platform used globally in data centers and corporate networks.
Zabbix allows us to implement:
Server monitoring
Network monitoring
SNMP monitoring
Syslog monitoring
SLA visualization
Custom dashboards
Real-time alerting
Because Zabbix is open-source and vendor-neutral, the monitoring environment remains transparent and maintainable over the long term.
Monitoring Designed for Non-Engineers
Traditional monitoring systems are often designed only for engineers and require deep technical interpretation.
We redesign Zabbix dashboards so they can be used by:
Executive assistants
Operations coordinators
Management teams
Dashboards can display:
Service health indicators
Site availability
Critical alert counts
Monthly uptime metrics
Simplified status panels
This enables:
First-line monitoring by non-engineers
Clear escalation procedures
Reduced operational overhead for executives
Monitoring should support decision-making, not burden leadership with technical interfaces.
Real-Time Alerting
Zabbix supports fully real-time detection and notification.
Typical monitoring targets include:
VPN status
WAN latency
Packet loss
Server resource usage
Network device status
Routing events
Alerts can be delivered through:
Email
Chat systems
Webhooks
Notification gateways
This ensures that incidents are reported immediately rather than discovered retrospectively.
AI-Assisted Log Analysis
Real-time alerts alone are not sufficient if log interpretation depends on a specific engineer.
Our approach combines:
Standard CLI log retrieval
Plain-text log storage
AI-assisted analysis when required
Typical workflow:
Zabbix detects an anomaly
Secure login to the device
Execute standard log command
Retrieve plain-text logs
Analyze manually or with AI assistance
By keeping logs in readable text format, the system avoids dependency on proprietary parsers or custom software.
AI assistance allows:
Rapid summarization of large logs
Identification of critical events
Pattern recognition
Report preparation
This significantly reduces operational dependency on individual engineers.
Reporting Capabilities
The monitoring environment can generate structured reports using:
Graphs
Availability statistics
Alert summaries
Performance trends
Reports can be delivered in:
PDF format
Graph-based summaries
Executive reports
Periodic operational reviews
These reports help management understand:
System reliability
Incident frequency
Infrastructure trends
Operational risk
without requiring technical interpretation of raw logs.
Maintainability and Transparency
We intentionally avoid proprietary monitoring systems that create long-term vendor dependency.
Instead, we design monitoring environments based on:
Open-source platforms
Standard protocols
Human-readable logs
Transferable operational procedures
This ensures that the monitoring system remains understandable and maintainable even if personnel change.
Monitoring systems should remain operable and auditable for years, not just during initial deployment.
Scalable Architecture
The same monitoring design can scale from:
Small offices
Multi-site enterprises
Data centers
without requiring replacement of the core platform.
Because Zabbix does not rely on per-device licensing, the system can grow without exponential cost increases.
Data Center Audit: Conducted by the executive and his/her team of assistants
Deterrence created when a CIO visually inspects each individual connection
To maintain a visible on-site presence and keep operations disciplined. To ensure that negligence or sabotage does not go unnoticed.
When conducting a data center audit, the external appearance—particularly the cable routing and termination—will likely become the central focus of the inspection. In many of the data centers we have been involved with, we have witnessed “severely problematic” cabling on two occasions over the past 20 years. (The example shown here is a simplified reproduction created within an environment under our supervision.)
First, we present an example of incorrect cabling.
Reason this is incorrect: If the lower device fails, the upper device would also need to be removed in order to access it. If these two units are configured in a redundant pair, both the primary and secondary systems would end up being removed together.
Although the number of cables in this sample photo is limited, most machines in commercial operation typically have a much higher cable count. If the number of cables is low, it often means that the cost of each available port is being underutilized.
Site inspections conducted by executive leadership should also incorporate a cost-efficiency perspective.
Next, we present an example of proper cabling.
With this approach, either the primary or the secondary unit can be replaced independently in the event of a failure.
“`html
Technical Inquiry
If this article relates to your network architecture, security design,
or infrastructure modernization, feel free to contact us.
Typical network architecture solutions designed and implemented by GIT.
These patterns are derived from real enterprise environments and long-term operational experience.
Let’s Expand the Secretarial Staff and Improve Their Compensation — Strengthening ROA Through Operational Efficiency
Are You Still Relying on Complex, Latency-Prone Monitoring Systems?
Our Windows-based network monitoring application is designed so that executives can operate it directly when needed. However, continuous operation is best delegated to trusted support staff while maintaining full executive visibility.
Executives Should Focus on Decisions — Not Tool Operation
Rather than having executives operate monitoring terminals themselves, these responsibilities should be entrusted to trusted executive support staff. Executives must retain visibility at all times, but operational handling should be delegated to those who support them directly.
Our monitoring solutions are designed precisely for this structure: providing executive-level visibility while allowing trusted staff to handle day-to-day interaction with the system.
Capital expenditures on IT assets reduce ROA, but investments in human capital do not.
Monitoring Teams Are Ideal Entry Roles for Career Switchers — Build Sustainable In-House Assets Instead of Expensive Outsourcing Without Worsening ROA
Let’s Expand the Secretarial Staff and Improve Their Compensation
Managers and Subordinates May Compete — Secretarial Staff Unite the Organization Instead of Dividing It
Managers and subordinates are often placed in competitive structures by design. Performance evaluations, promotion paths, and budget ownership can unintentionally turn colleagues into rivals.
This internal competition fragments organizations and slows decision-making. It creates defensive behavior instead of operational stability.
Administrative and secretarial staff function differently. Their role is not to compete for hierarchy but to support continuity, coordination, and trust across departments.
Investing in strong administrative teams reduces internal friction, improves information flow, and stabilizes operations. These roles create alignment rather than rivalry.
If organizations want to reduce internal division, the solution is not more layers of management competition — it is strengthening the staff who connect people rather than rank them.
IT Investment Provides Temporary Tax Relief but Expands Future Taxable Base
Capital Expenditure Defers Taxes — It Does Not Eliminate Them
Increasing Assets Changes the Timing of Taxation, Not Its Existence
“`html
Technical Inquiry
If this article relates to your network architecture, security design,
or infrastructure modernization, feel free to contact us.
Typical network architecture solutions designed and implemented by GIT.
These patterns are derived from real enterprise environments and long-term operational experience.
The primary purpose of this page is to demonstrate a practical, hardware-level understanding of quantum computer principles.
This is not a theoretical document. It is evidence derived from a working bench environment where analog electronics, phase behavior, and interference-based reasoning converge.
Quantum computation at the hardware level is governed by physical variables:
phase
current
magnetic flux
interference
temperature
noise
non-separation of input and output
The Toybox bench serves as an observation platform where these relationships are reconstructed in physical form.
Wiring Disclosure Policy
All wiring shown in this environment is intentionally undisclosed.
The visible configuration represents only the observation layer. Signal paths, coupling structures, and phase routing are not publicly documented.
This is a deliberate decision to preserve the integrity of the experimental framework while still presenting evidence of hardware-level understanding.
Enlarged view / Magnified view
Items I forgot to include / Omitted items(Wiring that can hardly be called professional.)
Analog Synthesis of Phase Modulation and Superconducting Coils
Phase as a Physical Variable
Phase modulation is a core element in understanding superconducting quantum hardware.
In such systems, the following coexist and evolve simultaneously:
phase
current
magnetic flux
interference
Computation is treated as a continuous electromagnetic interaction space rather than a sequence of discrete logic gates.
Coil as Memory, Operation, and Medium
Within superconducting architectures, a coil can simultaneously act as:
a storage element
an operational element
an interference medium
This leads to a non-separable structure where:
Input = Operation = Output
The Toybox arrangement reflects this understanding through a simplified observation environment.
All wiring is undisclosed. Only the physical observation surface is presented.
Interference as Computation
Computation Occurs in the Field
In classical systems:
Input → Operation → Output
In quantum hardware:
Input = Operation = Output
Computation occurs within the interference field itself.
Under a superconducting-coil model:
phase is introduced
interference evolves
observation extracts state
The system behaves as a unified computational space rather than a chain of operations.
Bench Representation
The Toybox environment expresses this structure through:
distributed observation nodes (LEDs)
spatial wiring paths
assumed interference regions
The visible structure demonstrates correct hardware intuition. The invisible structure remains private.
All wiring is undisclosed.
Hardware-First Understanding
Before Software
Most discussions of quantum computing begin with algorithms. This page begins with hardware.
Understanding requires awareness that:
measurement alters the system
coherence is physical
phase relationships dominate behavior
temperature and noise define operational limits
These constraints are considered at the bench level.
Evidence Through Physical Arrangement
The image presented here is not decorative. It is evidence that:
interference-centric reasoning is present
coil-based computation is understood
phase relationships are treated as primary
hardware reality precedes abstraction
This is not a finished quantum processor. It is a working environment built by someone who understands how such hardware operates.
Toybox as an Observation Platform
Practical Hardware Intuition
Large-scale quantum systems require specialized facilities. However, the underlying hardware principles can be understood through:
analog phase systems
coil-based reasoning
interference modeling
bench-level reconstruction
The Toybox serves as a compact observation platform where these ideas are physically organized and examined.
The Advantages of Compromise: Fewer Screw Types as a Design Philosophy
Start with a photo of an SVBONY device. One immediate observation is the small number of screw types used.
This is not about aesthetics. It is about maintainability.
Reducing the number of screw types brings clear advantages:
Fewer tools required on site
Faster maintenance and replacement
Lower risk of losing critical parts
Simpler inventory management
Higher probability that anyone can repair it
Visual perfection may be sacrificed, but operational continuity improves.
This is compromise used as a deliberate engineering strategy.
A Thought Experiment on Standardization
News frequently shows images of destroyed military hardware. Yet the overall frontline situation often appears unchanged.
This leads to an interesting thought experiment.
Imagine if the latest stealth aircraft and an 80-year-old armored vehicle shared the same screw standards.
This is not a claim. It is a design imagination exercise.
Common fasteners across generations would mean:
Simplified logistics
Unified toolchains
Faster field repair
Reduced training complexity
In other words:
Sustainable operation can outweigh peak performance.
Reducing the number of screw types is not merely simplification. It is a philosophy of continuity.
Antenna Tower Cabling: Safety Over Appearance
Next comes a photo of the antenna tower cabling.
The goal was to improve:
Physical strength
Structural safety
Serviceability
A perfectly clean visual layout was the original target. However, the evening sun reflecting off the Starlink router looked too good to ignore.
So a compromise was made.
The current state was photographed and published as-is.
Waiting for perfection can delay progress. Publishing the present state allows iteration.
This is another form of productive compromise.
The log-periodic antenna is used for astronomical observations with a spectrum analyzer. The broadband antenna on the far left is used to record Jupiter’s decametric emissions on the spectrum analyzer display.
Next Objective: Quantum Computing via Starlink
A friend introduced a service that allows about ten minutes of free quantum computer usage per month. The system appears to be located in New York.
The next experiment will focus on:
Latency over Starlink
Session stability
UI responsiveness
Impact of satellite routing
The goal is not deep research. The goal is observation.
What happens when satellite internet meets remote quantum hardware?
That alone is worth testing.
Compromise Is Not Failure
Fewer screw types. Publishing imperfect cabling. Testing within free-tier limits.
All of these share a common principle:
Continuity over perfection.
Compromise, in engineering and operations, is not surrender.
It is design.
My Day Off
I played the keyboard for the first time in over 25 years. Were 88 keys always this cramped? (Maybe it just doesn’t actually have all 88. Still, when you’re a dual-income household raising kids, the kitchen situation is… well, you know.)
To keep from taking the lead myself, I played along with a drum-machine preset and ended up performing the longest single piece of my life. Maybe around 30 minutes.
With a canned coffee in one hand, though. Figuring I’d hog the rhythm if I tried to hear my own sound, I muted the keyboard and played anyway. Since it turned out to be “something I could do if I tried,” I realized I don’t need to do it again. Music might as well be improvisation only.
And yet, I can’t shake the feeling that even a sheet of paper with my kids’ timetable counts as personal information. I almost want to erase even the parts reflected in the toy piano.
I played using only both thumbs.
That’s when I realized: with only two notes, there’s no majority vote. It’s the third note that lets you emphasize, soften, or decorate things—and somehow that’s what makes it unpleasant. But strangely, after I stop playing and some time passes, a melody comes out of my mouth.
Then I put words on that melody—something like, “Even if the blue sky disappears, it’s okay, because the stars are still there.” And those spontaneously spoken words trigger a modulation—like when repeating “It’s okay” in succession creates a new melody. I noticed this a little while ago in the past, on guitar, when I used a technique that relied on just a single string.
Oh, right. I bought a violin for kids.
People say I’m reckless. About me—the one who carefully erases fingerprints before uploading photos. Even so, I can’t stop worrying about things like vein authentication and that whole area.
1,300 yen. At a shop like Hard Off. I’m going to attach a bunch of motors to it and pick up where “that time” left off.
I’ll also briefly touch on something I’ve already written about on my personal blog.
On guitar, it’s surprisingly fun to fret all the strings at the same position and play famous classical pieces that way. I’ll refrain from mentioning here that the opening of Schubert’s Erlkönig sounds a lot like Bay Area heavy-metal crunch.
Even Then, Screws Alone Remain SQC
SQC as Discipline
In this context, SQC is treated as a discipline applied to fasteners. It is the deliberate restriction of screw types, sizes, and drive standards in order to maintain serviceability, tool compatibility, and repeatable assembly over time.
The objective is not aesthetic consistency but operational stability. A constrained fastener set reduces tooling variance, minimizes assembly errors, and improves field maintenance. When the allowable range of screw types is fixed early in design, downstream processes become predictable and repairable.
The SVBONY tripod examined here uses a narrow Torx range (T5–T20). This range is sufficient for structural and accessory interfaces without introducing redundant drive types or unnecessary size expansion. The selection demonstrates controlled variation rather than maximal flexibility.
Fastener inconsistency is often attributed to manufacturing origin. In practice, inconsistency is a function of system discipline rather than geography. Without constraints, any supply chain accumulates thread variance, head-type proliferation, and tool incompatibility. With constraints, even mid-tier components remain maintainable because the surrounding system assumes a fixed toolset and repeatable interfaces.
SQC in fasteners therefore operates as a long-term constraint mechanism. It prevents uncontrolled variation and preserves mechanical interoperability across product revisions and maintenance cycles.
Absence of Competing Drive Standards in Retail Supply
In many hardware and construction supply stores used by Japanese contractors, Torx fasteners and drivers are rarely stocked. This is notable not as a matter of preference, but as a supply-chain observation.
Where multiple drive standards compete in the same retail channel, tooling and fastener ecosystems tend to converge toward the most serviceable and damage-resistant interface. Where such competition does not occur, legacy drive types remain dominant and alternative standards do not enter routine procurement.
The absence of Torx in these retail environments indicates a lack of active competition at the tool-and-fastener interface level. Without competing standards present in the same procurement channel, convergence pressure does not form, and the installed base remains unchanged.
Drive Standard Selection and Procurement Inertia
In flat-pack furniture systems intended for user assembly, the absence of Torx fasteners is expected. These systems prioritize low tooling requirements, minimal user friction, and compatibility with common household drivers.
However, in retail channels supplying professional construction contractors, the complete absence of Torx fasteners and drivers presents a different condition. In environments where multiple drive standards coexist in procurement channels, competition between interfaces typically drives convergence toward those offering higher torque transfer stability and reduced cam-out. Where such alternatives never enter the supply chain, legacy standards persist without direct technical comparison.
This condition reflects procurement inertia rather than a deliberate engineering choice. When competing fastener interfaces are not present in the same distribution network, evaluation pressure does not occur, and installed practices remain unchanged.
However, it is likely that this is simply a limitation of my own familiarity with these stores. Such supply shops tend to open early. I will visit one first thing tomorrow morning to confirm. And, as usual, I will probably end up making another unnecessary purchase just to justify the parking fee.
All evidence on this page was built by the engineer described below.
All systems, logs, and tools shown on this page were designed and implemented by the same engineer. Specializing in vendor-neutral network and security architecture with an evidence-first approach.
During a discussion about emergency generator fuel replacement in a data center, a simple question regarding diesel degradation and storage conditions resulted in an unexpected pause.
During a discussion about emergency generator fuel replacement in a data center, a simple question regarding diesel degradation and storage conditions resulted in an unexpected pause.
It was not intended as criticism. Only a verification of whether documented assumptions matched actual operating conditions.
Typical network architecture solutions designed and implemented by GIT.
These patterns are derived from real enterprise environments and long-term operational experience.
A Network That Keeps Operating Even Under Wartime Conditions
Concept: Security Events Directly Trigger Network Path Control
In environments where service continuity is critical, the network must be able to continue operating even when key infrastructure components become compromised, overloaded, or untrusted. This design proposes a mechanism in which security-relevant syslog events act as triggers for immediate and deterministic network path changes.
When predefined security conditions are met, an automated control sequence modifies VRRP priority values to shift the active gateway role to an alternate firewall or IPS device from a different vendor. This allows the network to continue operating while isolating or bypassing potentially compromised equipment.
The intent is not only failover for availability, but failover for trust preservation.
Architecture Overview
The system consists of four logical layers:
Event Detection Layer Security-related syslog messages are received from firewalls, IPS devices, and core infrastructure. Only specific, pre-correlated events are treated as actionable triggers.
Decision Layer A control host—preconfigured and isolated—evaluates whether the received events meet the threshold for failover. Conditions may include:
Severity level
Repetition count
Source correlation
Time window thresholds
Control Execution Layer Once validated, an automated macro or scripted control process connects to network devices and modifies VRRP priority values. This forces the gateway role to migrate from the primary security appliance to an alternate vendor’s firewall or IPS path.
Stability and Recovery Layer To prevent oscillation or repeated failover:
Cooldown timers are applied
Manual confirmation may be required for restoration
Health checks confirm stability before reverting
Why VRRP Priority Manipulation
VRRP provides a deterministic and vendor-neutral mechanism for gateway role selection. By adjusting priority values instead of shutting down interfaces, the system can:
Preserve routing consistency
Maintain predictable failover timing
Avoid full routing reconvergence
Keep recovery reversible
This approach allows failover logic to be externally controlled while still relying on standard L3 redundancy protocols.
Cross-Vendor Failover as a Security Strategy
Traditional high-availability designs assume identical hardware pairs. However, in adversarial conditions, homogeneous redundancy can become a liability.
A heterogeneous security path offers:
Reduced single-vendor attack surface
Independent firmware and control planes
Divergent vulnerability profiles
Operational resilience against targeted exploits
Failing over from one vendor’s device to another is not only redundancy—it is defense diversity.
Control Point Design Considerations
The control host that initiates VRRP changes must be:
Isolated from general user networks
Hardened and access-restricted
Able to operate even during partial infrastructure failure
Capable of manual override
Automation should assist the operator, not replace situational awareness. The system is designed so that human authority remains intact even during automated transitions.
Operational Safeguards
To ensure stability, the following safeguards are recommended:
Event correlation instead of single-log triggers
Rate limiting of failover actions
Mandatory cooldown intervals
Verification of post-failover reachability
Logging of all control actions
Failover should be decisive, but never impulsive.
Trigger Conditions Example
A failover may be initiated only when all of the following are true:
Multiple high-severity security logs detected
Consistent source or signature pattern
Threshold exceeded within defined time window
Primary path health check fails or becomes uncertain
This reduces the risk of malicious or accidental triggering.
Recovery Philosophy
Automatic restoration to the original path should be conservative. In uncertain environments, stability outweighs symmetry. Manual verification before restoring original priority values ensures that compromised components are not prematurely trusted again.
Intended Use Cases
Intended Use Cases
Critical infrastructure networks
Research environments requiring continuity
Multi-vendor security architectures
Remote or constrained operational sites
Situations where physical intervention is delayed
The goal is not militarization, but survivability: a network that continues to function even when trust in individual components is temporarily lost.
Conclusion
A network that keeps operating under extreme conditions must be able to change its own structure in response to threats. By combining security event detection with controlled VRRP priority manipulation, the network gains the ability to reconfigure itself without full outage.
Resilience is not merely redundancy. It is the capacity to adapt while still moving forward.
“`html
Technical Inquiry
If this article relates to your network architecture, security design,
or infrastructure modernization, feel free to contact us.
Typical network architecture solutions designed and implemented by GIT.
These patterns are derived from real enterprise environments and long-term operational experience.
Continuous Normality Reporting, Delivered Directly to the CIO
Direct from Network Devices to the CIO — With Regional Employment Built In
Core Concept
The CIO Personally Monitors Normality
Heartbeat signals from network devices are delivered directly to the CIO.
This allows the CIO to state with confidence:
“I personally monitor system normality at all times.”
The system provides continuous proof of operational awareness at the executive level.
Direct Device-to-CIO Architecture
Syslog for Events, Ping for Heartbeat
Network devices communicate directly with Heartbeat2CIO.
Syslog reports real events
Ping confirms ongoing reachability
Combined, they form a reliable heartbeat
No intermediate interpretation layer is required.
CIO Participation in Development (DX Positioning)
Not a Tool Bought Somewhere — A System the CIO Helped Build
Heartbeat2CIO supports a governance model in which the CIO can state at a shareholder meeting:
“This is not a tool we simply purchased. It was implemented as part of our DX initiative, and I personally participated in its design and development.”
By positioning the system as a DX support effort rather than a generic purchased tool, the organization demonstrates:
Executive ownership
Direct accountability
Technical understanding at the leadership level
Transparent governance
This strengthens credibility with shareholders and stakeholders.
Minimal Monitoring Infrastructure
No Monitoring Staff Required for Observation
Heartbeat2CIO removes the need for:
Dedicated monitoring teams
Large NOC environments
Heavy monitoring platforms
The CIO receives direct signals from the network itself.
Physical Maintenance Still Matters
Hardware Replacement Requires People
When devices must be replaced in a data center,
human intervention is still necessary.
Hardware maintenance cannot be automated away. This is not a flaw — it is a feature.
Regional Employment Creation
Supporting Jobs in Local Cities
Physical device replacement and on-site support
create meaningful employment opportunities in regional and local cities.
Typical network architecture solutions designed and implemented by GIT.
These patterns are derived from real enterprise environments and long-term operational experience.
※日本国内案件については、元請けITベンダー様経由での技術支援を基本としています。 Stop flying engineers. Fix the network.
Network Architecture That Eliminates Unnecessary Business Trip
Slash Travel Costs with Network Design
K.K. GIT designs and implements network architectures that reduce travel, lower OPEX, and enable reliable remote operations across Japan.
If engineers need to travel just to deploy routers or capture packets, the issue is not geography. It is network architecture.
We help organizations operating in Japan build remote-first networks that support diagnostics, deployment, and expansion without unnecessary dispatch.
Our work combines architecture design and implementation support, ensuring that networks function correctly in real operations.
Eliminate Nationwide Travel with Remote Layer-3 Design
In one environment, engineers were traveling nationwide to install routers at each new site.
K.K. GIT redesigned the network using structured Layer-3 segmentation and remote activation planning.
New locations could be brought online by creating SVIs on existing infrastructure.
No site visit required. No travel booking. No rollout delay.
Travel cost dropped immediately, and nationwide rollout became predictable and fast.
This is not convenience automation. This is architecture designed for remote operations at scale.
Stop Business Trip Engineers Just to Capture Packets
In another case, an engineer traveled on-site only to run a packet capture.
The distance was within Tokyo.
The visit revealed the real issue: the network required physical presence for basic diagnostics.
K.K. GIT redesigned the environment to support:
remote diagnostics
structured capture points
pre-deployment validation
remote troubleshooting
operational visibility
immediate reduction in travel cost
lower OPEX
faster site rollout
reduced operational overhead
improved diagnostic response time
scalable remote operations
After redesign, diagnostics could be performed remotely, without dispatch.
Appendix: Declining Cost Performance Caused by Leaving PCs Underpowered
Many clients continue using PCs with insufficient performance. The inevitable result is delayed work. Unnecessary labor (overtime pay) and outsourcing costs increase, and your company’s credibility declines as a consequence.
Designed for Companies Operating in Japan
K.K. GIT supports:
foreign-owned companies in Japan
English-speaking IT teams
distributed offices
CIOs managing nationwide operations
Our goal is simple:
Reduce travel. Increase control. Stabilize operations.
Remote-First Network Operations
K.K. GIT designs and supports networks that enable:
remote operations from day one
reduced travel cost
nationwide rollout without dispatch
Layer-3 segmentation
implementation-ready architecture
fast remote diagnostics
predictable deployment
We understand the operational cost structure of running infrastructure across Japanese regions and the friction caused by unnecessary site visits.
Every unnecessary trip is a design failure. We fix the design.
Outcomes for CIOs and Leadership
Organizations working with K.K. GIT typically see:
Network growth should not require proportional growth in travel.
When expansion increases dispatch frequency, the architecture must be reconsidered.
Contact
K.K. GIT Tokyo, Japan
For architecture review, redesign, or implementation support: +
“`html
Technical Inquiry
If this article relates to your network architecture, security design,
or infrastructure modernization, feel free to contact us.
Typical network architecture solutions designed and implemented by GIT.
These patterns are derived from real enterprise environments and long-term operational experience.
Direct signal path from network infrastructure to executive decision.
Vendor-neutral network & security engineering with custom internal tooling.
We design infrastructure and build the tools that operate inside it.
Vendor-neutral network & security engineering — plus custom internal tools
We provide vendor-neutral network and security architecture, troubleshooting, and implementation support. When off-the-shelf tooling is too heavy, too indirect, or not allowed in restricted environments, we also build lightweight internal applications that deliver direct operational signals.
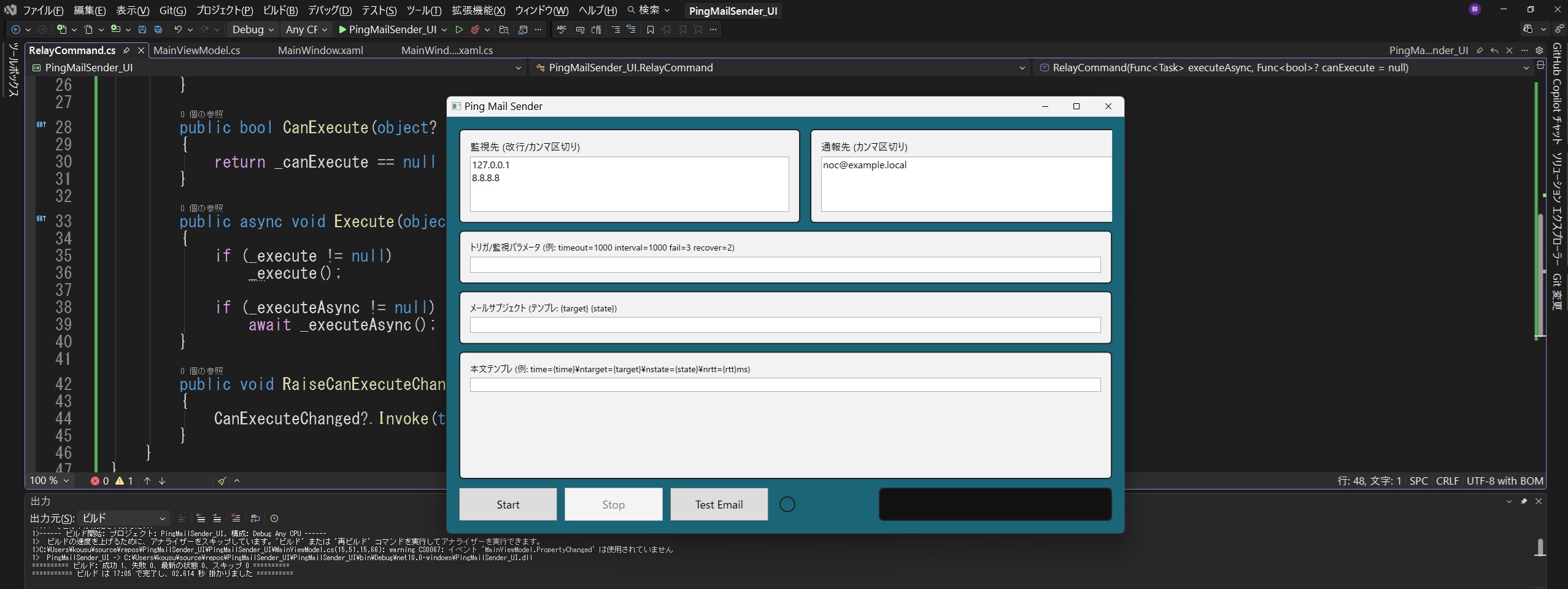
Example: Windows Ping Monitoring & SMTP Alert Application
This Windows desktop application performs continuous Ping monitoring and sends email alerts via an internal SMTP relay. It is designed for environments where external monitoring SaaS, cloud dependencies, or third-party APIs are not acceptable.
What this page proves
We can design monitoring logic that operators can trust (DOWN / RECOVER)
We can build Windows desktop software (WPF) tailored to your workflow
We can integrate cleanly with internal infrastructure (SMTP relay)
We deliver evidence-driven outputs (reproducible checks and logs)
Where this approach fits
Security-restricted or closed networks
On-premise / factory / isolated infrastructure
Environments that require auditable, minimal tooling
Teams that need direct signals rather than another dashboard
In addition to Windows desktop applications, we also build lightweight internal automation tools in Python. This example monitors Syslog messages, detects specific patterns, and sends email notifications via an internal SMTP relay. It is designed for environments where reliability, auditability, and low operational overhead matter more than dashboards.
What it does
Receives Syslog (UDP/TCP) and writes logs to a file
Matches defined patterns (keywords / regex) in near real time
Sends email alerts through an internal SMTP relay
Supports multiple alert rules and destinations
Runs as a small, auditable service inside closed networks
Why this approach
Many organizations already have Syslog flowing across their infrastructure, but incident visibility is often delayed by tooling complexity or operational friction. We build tools that reduce time-to-signal by turning raw events into actionable notifications without external dependencies.
Typical environments
Security-restricted or isolated networks
On-premise infrastructure and appliances
Operational teams that need direct signals (mail) instead of dashboards
Situations where SIEM integration is not feasible or not desired
Key capabilities we deliver
Vendor-neutral network and security engineering
Automation and tooling for incident detection and response
SMTP-based internal notification routing
Evidence-driven troubleshooting and reproducible test logs
Contact
Contact us to discuss constraints, requirements, and a verification plan.
These tools are typically delivered alongside network and security design engagements.
“`html
Technical Inquiry
If this article relates to your network architecture, security design,
or infrastructure modernization, feel free to contact us.
Typical network architecture solutions designed and implemented by GIT.
These patterns are derived from real enterprise environments and long-term operational experience.