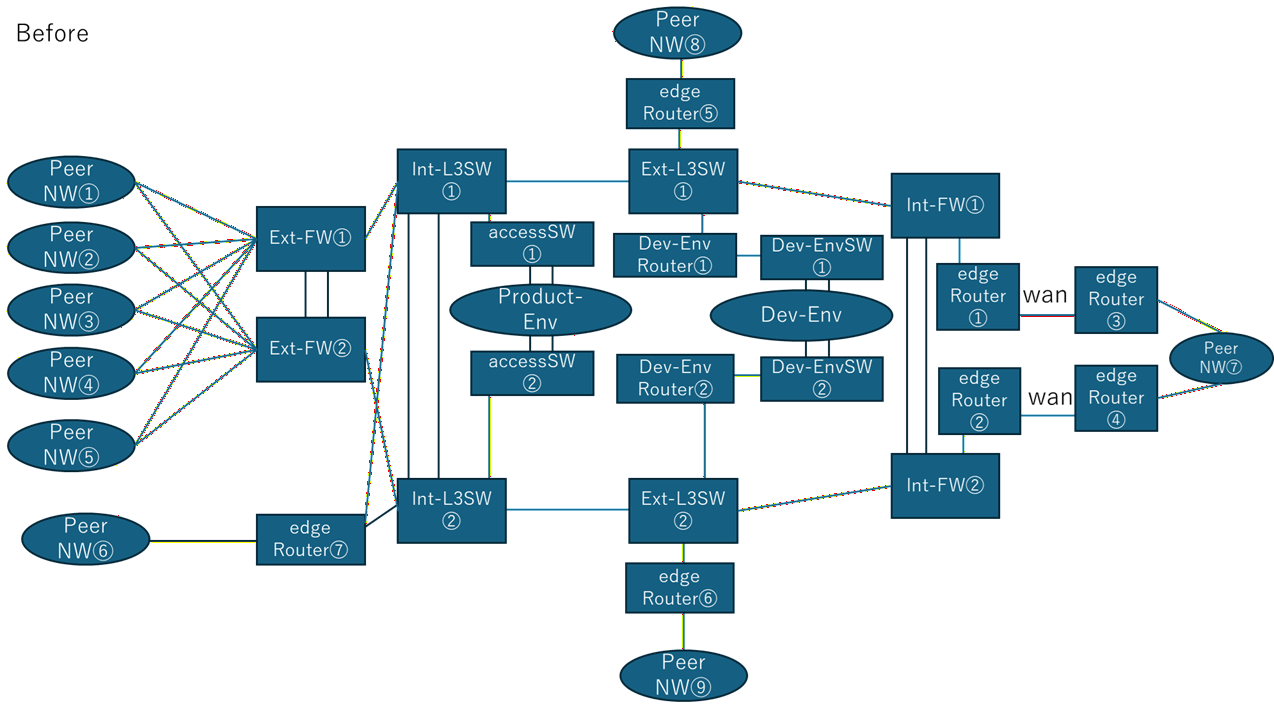
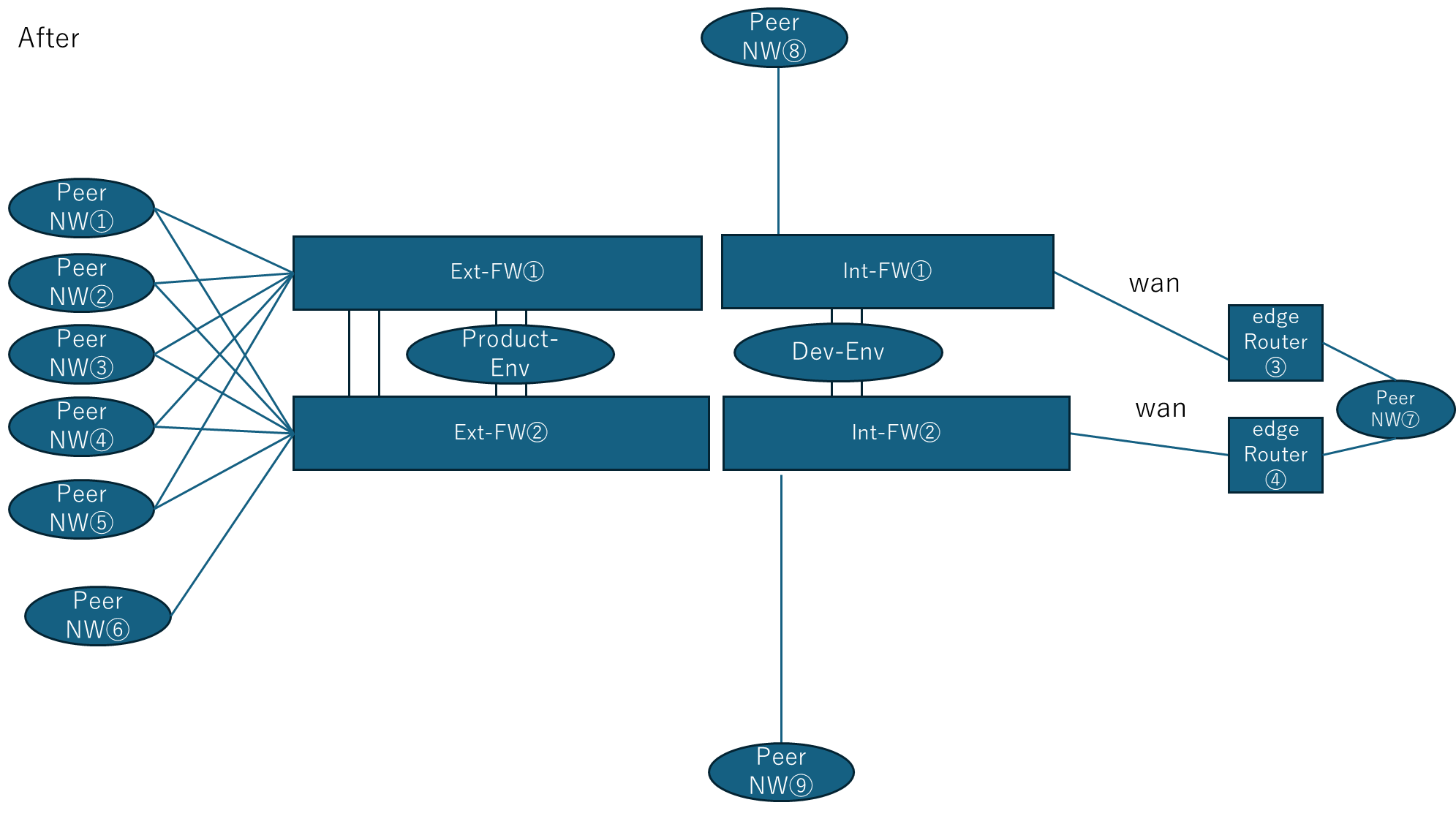
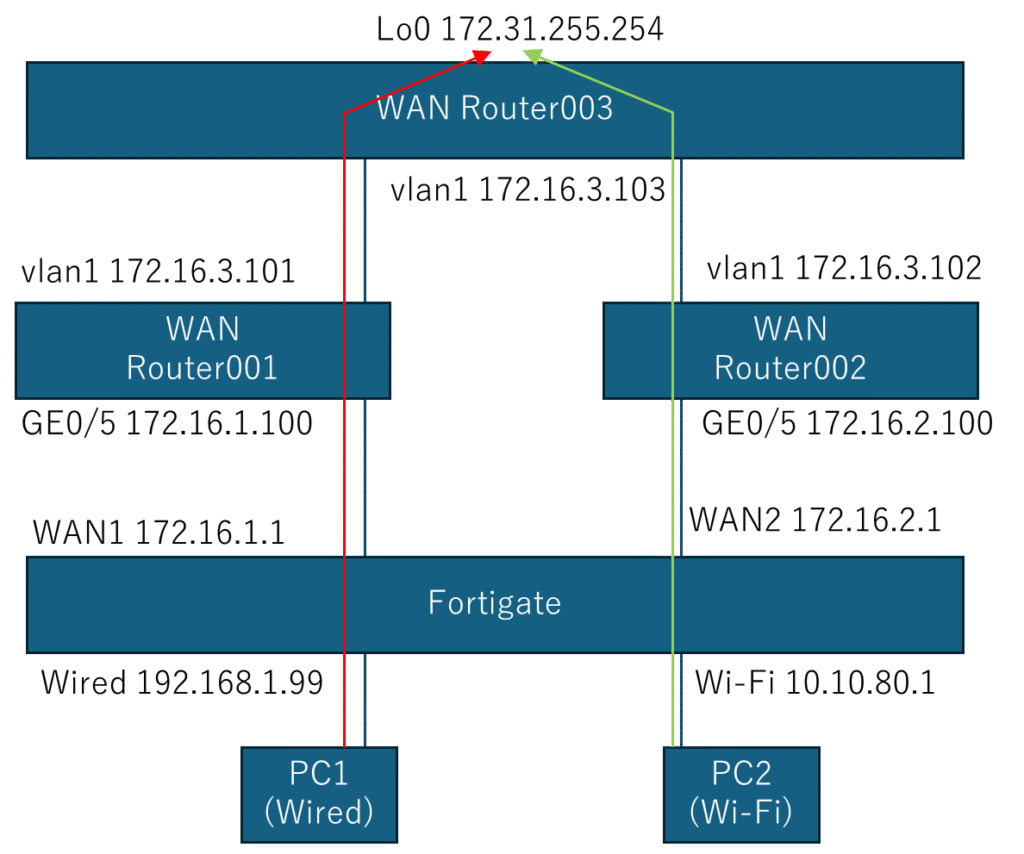
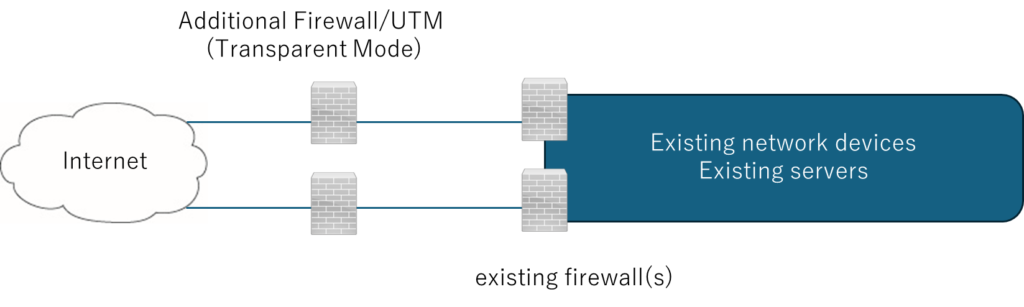
Resilient Satellite-Backhaul Architecture for Interference-Prone Regions
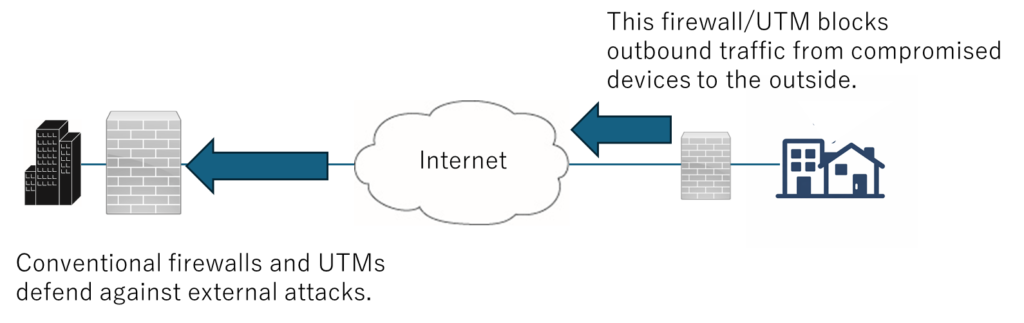
This document presents a carrier-grade satellite backhaul design optimized for post-conflict and interference-prone environments.
The primary objective is not continuous uptime at all costs, but guaranteed recoverability under degraded power, packet loss, and intentional radio interference.
This architecture does not compete with satellite connectivity providers.
Instead, it provides an operations-resilient overlay that runs on top of existing commercial satellite infrastructure.
Design Principles — Recovery Before Availability
Non-Competitive Overlay on Existing Satellite Networks
This design assumes the use of existing commercial satellite networks already operating in Northern Europe and adjacent regions.
The goal is to strengthen operational resilience without competing with connectivity providers.
Key principles:
- Use existing satellite backhaul as the underlay
- Provide resilience at the network-operations layer
- Support multi-operator satellite environments
- Avoid replacing or competing with satellite carriers
- Deliver recovery-oriented design rather than bandwidth
The system is positioned as an operations resilience layer, not a connectivity product.
L3-First Overlay Architecture (EVPN/VXLAN)
Traditional L2 extension across unstable infrastructure leads to cascading failures.
Therefore, this architecture prioritizes Layer-3 VXLAN (L3VNI) segmentation.
Core components:
- EVPN control plane (MP-BGP)
- VXLAN data plane
- L3VNI for VRF segmentation
- Minimal L2 extension (site-local only when required)
Benefits:
- Fault containment within VRFs
- Prevention of broadcast storms and loops
- Faster recovery after link degradation
- Simplified post-outage convergence
This approach ensures that local misconfigurations or infrastructure instability do not propagate across the entire network.
Operations-First Connectivity (OAM VRF)
Operational connectivity is isolated into a dedicated VRF:
VRF-OAM (Operations and Management)
Functions carried within this VRF:
- Device management (SSH/HTTPS)
- Telemetry and monitoring
- EVPN/BGP control plane
- Logging and diagnostics
- Remote recovery actions
Design rules:
- OAM traffic shares the same satellite link as service traffic
- Strict QoS prioritization ensures OAM survives congestion
- Bandwidth requirements are minimal (sub-Mbps acceptable)
- OAM traffic is strictly limited to recovery-critical functions
- No large data transfers permitted in OAM VRF
Even when service traffic collapses, recovery control remains available.
Interference-Aware Satellite Operations
Jamming-Resilient Control Behavior
This design assumes persistent low-intensity radio interference such as:
- Packet loss bursts
- Latency fluctuations
- Short intermittent outages
- Throughput degradation
The objective is not to defeat jamming at the physical layer, but to prevent network instability caused by control-plane overreaction.
Key measures:
- Conservative BGP and EVPN timers
- Avoid aggressive failover triggers
- Introduce hysteresis in path selection
- Prevent control-plane flapping
- Maintain stable session state under degraded conditions
The system prioritizes stability under degradation rather than rapid failover.
Minimal OAM Survival Channel
Operational traffic is intentionally constrained to a minimal footprint.
Allowed traffic:
- Management access
- Monitoring
- Control-plane signaling
- Emergency configuration actions
Disallowed traffic:
- Bulk log transfers
- Backups
- File transfers
- Heavy dashboards
- Continuous telemetry streams
The objective is to ensure that OAM traffic remains viable under severe bandwidth constraints without congesting the satellite link.
Failure Sequence and Recovery Order
Recovery is orchestrated in a defined sequence:
- Power stabilization
- OAM VRF recovery
- Control-plane re-establishment
- Service restoration
The design deliberately avoids attempting full service restoration simultaneously.
Instead, it ensures that operators regain control first.
Validation Using Cisco CML
Simulation Environment
Cisco Modeling Labs (CML) is used to reproduce the architecture and failure scenarios.
Simulated conditions include:
- High latency satellite links
- Packet loss
- Link instability
- Interference-like degradation
- Power interruption scenarios
Failure Scenarios Tested
Service Collapse Test
Service VRF failure is induced while verifying that OAM VRF remains reachable.
Interference Simulation
Variable packet loss and latency introduced to emulate radio interference.
Goal: prevent control-plane flapping.
Full Outage Recovery
Complete link loss followed by restoration.
Recovery order and convergence time are measured.
Automation and Reproducibility
Configuration and recovery procedures are automated.
- Legacy TeraMacro scripts translated into Python
- Automated configuration deployment
- Reproducible failure injection
- Publicly documented test outputs
This ensures that the architecture can be independently validated.
Collaboration Model
artnership with Satellite Operators
This architecture is designed to operate in cooperation with existing satellite providers.
Value delivered:
- Operational resilience
- Faster recovery after outages
- Fault containment
- Stable control-plane operation under interference
The design does not replace satellite connectivity.
It enhances survivability and recoverability.
Deployment Context
Applicable environments:
- Northern European infrastructure resilience programs
- Post-conflict reconstruction
- Disaster recovery communications
- Power-unstable regions
- Carrier ground station operations
Final Statement
The goal of this architecture is not absolute uptime.
The goal is recoverability.
When interference persists,
when latency fluctuates,
when power fails,
operators must retain control.
Operations survive first.
Services return second.
That is the foundation of resilient communications in unstable environments.
A Permanent Regional Backhaul Using One-to-Many GRE (mGRE) Without Encryption
In regions where electrical power is unstable, satellite internet must be designed for survival rather than peak quality.
Instead of pursuing traditional metrics such as throughput, latency optimization, or encryption-first security, this architecture prioritizes rapid recovery, minimal operational overhead, and tolerance for repeated device restarts.
Our approach uses multipoint GRE (mGRE) as a permanent regional backhaul fabric.
Encryption is intentionally omitted at the transport layer. This eliminates key rotation, re-negotiation delays, CPU overhead, and ongoing vulnerability remediation cycles tied to cryptographic stacks. The resulting network is simpler, more resilient to power loss, and easier to maintain across remote sites.
The guiding principle is not to prevent interruption, but to ensure that communication returns immediately after interruption.
What One-to-Many GRE (mGRE) Enables in Permanent Regional Links
mGRE allows multiple remote sites to join a shared tunnel domain without defining fixed tunnel destinations.
This removes the need to maintain separate point-to-point tunnels for each site and significantly reduces configuration complexity as the network grows.
For permanent regional satellite backhaul, this means:
- New sites can be added without restructuring existing tunnels
- Sites can drop and rejoin after power loss without manual intervention
- Routing adjacency can be restored quickly after restarts
- The network does not depend on stable Layer-2 state
The architecture assumes that outages will occur and focuses on rapid reintegration rather than continuous uptime.
Why Transport-Layer Encryption Is Intentionally Omitted
In unstable power environments, encryption often introduces more operational fragility than protection.
Key exchange failures, CPU constraints, tunnel renegotiation delays, and security patch cycles can all delay recovery after a restart.
By omitting IPsec and similar encryption mechanisms at the tunnel layer:
- No key management infrastructure is required
- Tunnel re-establishment is immediate after device reboot
- Firmware updates are less urgent
- Operational overhead in remote areas is minimized
Sensitive payloads can still be protected at higher layers where necessary, but the transport itself remains lightweight and resilient.
NAT and Carrier Constraints in Satellite Networks
Satellite connectivity frequently involves NAT or carrier-grade NAT.
This can interfere with traditional GRE operation and may introduce one-way reachability or session instability.
The design therefore assumes that:
- GRE transport must tolerate intermittent reachability
- Keepalive mechanisms should be minimal and lightweight
- Tunnel participation must be stateless and forgiving
Where direct GRE transport is blocked, encapsulation adjustments can be applied without changing the overall architecture.
The objective is not protocol purity but consistent regional connectivity.
Mutual Broadcast Model Across the Regional Fabric
Rather than forcing strict unicast recovery across unstable links, participating nodes can operate under a shared distribution model.
Each site transmits into the shared tunnel domain, and receiving nodes selectively process relevant traffic.
This does not rely on native Internet multicast routing, which is rarely available across satellite providers.
Instead, the shared tunnel environment provides a controlled domain where traffic distribution can occur without maintaining strict Layer-2 adjacency.
The result is a resilient communication pattern where nodes rejoin the network simply by re-establishing tunnel presence.
Using Rendezvous Points to Assist Route Recovery After Outages
To further improve recovery behavior in unstable power environments, the architecture incorporates a rendezvous point (RP) concept to assist with route re-establishment after node or link failure.
In a permanent regional backhaul where sites may power-cycle unpredictably, routing adjacency alone is not always sufficient for rapid recovery. A rendezvous point provides a stable reference node that allows participating sites to rejoin the overlay fabric without needing full mesh awareness at startup.
When a site comes back online after a power interruption:
- It re-establishes its tunnel presence toward the rendezvous point
- The rendezvous point serves as a temporary traffic convergence anchor
- Routing information can be re-learned incrementally
- Traffic can flow via the rendezvous point until optimal paths are restored
This model does not require strict multicast routing support from the underlying carrier.
Instead, the rendezvous point functions as a logical convergence node within the overlay, helping stabilize routing during periods of churn.
The rendezvous point can be implemented as:
- A central hub within the mGRE domain
- A lightweight control-plane anchor
- A temporary forwarding node during reconvergence
- A regional aggregation site
Once connectivity stabilizes, traffic may again flow directly between sites if routing policy permits.
The rendezvous point remains available as a fallback convergence mechanism during future disruptions.
By incorporating a rendezvous-based recovery assist mechanism, the network gains an additional layer of resilience.
Rather than requiring all sites to rediscover one another simultaneously after outages, each site only needs to regain contact with a known anchor.
This reduces reconvergence time and supports predictable restoration of regional connectivity.
Operational Priorities for a Permanent Regional Satellite Backhaul
To maintain stability across a long-lived regional deployment, the network is designed around predictable recovery rather than continuous uptime.
Key priorities include:
- Minimal configuration state per site
- Fast reintegration after power restoration
- Reduced dependency on ARP or MAC learning
- Simplified routing convergence
- Clear separation between monitoring and transport
This approach allows the infrastructure to remain functional even as individual nodes restart, relocate, or temporarily disconnect.
Strategic Positioning
By publicly acknowledging that traditional quality metrics are not the primary design goal in unstable-power regions, this architecture establishes a distinct operational model.
Later entrants may focus on performance improvements, but the foundational backhaul layer—designed for persistence and rapid recovery—remains in place.
This positions the network as a permanent regional communication fabric rather than a performance-optimized link.
“`html
Technical Inquiry
If this article relates to your network architecture, security design,
or infrastructure modernization, feel free to contact us.
Email:
contact@g-i-t.jp
Related Architecture Solutions
Typical network architecture solutions designed and implemented by GIT.
These patterns are derived from real enterprise environments and long-term operational experience.
View Network Architecture Solutions
Back to Home
“`